
Was ist New SQL?
Was ist NewSQL und vor allem, was daran ist so „new“? Ich darf schon mal so viel verraten, dass es sich hier nicht um die Neuerfindung des Rads bzw. der Datenbank handelt. Vielmehr setzt man auf Altbekanntes und wandelt es zum Gunsten der Datenhaltung ab.

NewSQL
Wie einleitend erwähnt stellt NewSQL keine Neuerfindung der gesamten Datenbanktechnologie dar. Jedoch wurde die klassische SQL-Datenbank abgewandelt, so dass es möglich ist gigantische Datenmengen zu speichern.
Ziel von NewSQL
Die Intention von New SQL ist die Haltung von sehr großen Datenmengen. Dazu wird das klassische SQL (auch abschätzig „OldSQL“ genannt) mit der Big-Data-Technologie kombiniert. Hier stellt sich schon raus, dass der Begriff NewSQL kein technisch korrekter ist, sondern vielmehr ein sehr werbetreibender Terminus.
Anwendung von NewSQL
Die Big-Data-Technologie („New SQL“) wird überall da angewandt wo gigantische Datenmengen entstehen, die nach dem OLTP-Prinzip (bei Anfrage sofortige Antwort) funktionieren. Beispielsweise bei Cloud-Services oder aber auch Google. Gerade bei Google müssen tausende von Daten kombiniert werden um diese sofort als Suchergebnis auszuliefern.
Aufbau von New SQL
Der grobe Aufbau der New SQL oder auch Bigdata-Datenbanken ist der gleiche wie bei den bisherigen „Old SQL“ Datenbanken. Jedoch unterscheiden sich die Technologien im Detail.
Layer 1: Query Distribution
Ganz klassisch werden hier die Abfragen koordiniert. Bei herkömmlichen Datenbanken sind das die SQL-Befehle („SELECT * FROM table„). Bei den BigData-Datenbanken hängt die Abfragesprache ganz von der eingesetzten Datenbank ab: d.h. kein StandardQL.
Layer 2: Data Distribution
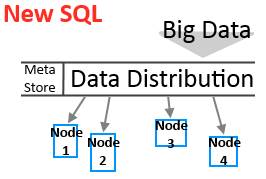
NewSQL
Die Data-Distribution Schicht kümmert sich in New SQL darum, wie die Datenverteilt werden. Hier weicht die Bigdata-Technologie gravierend von der klassischen OldSQL-Datenbank ab. Denn statt Alle Daten in ein Verzeichnis bzw. Knoten zu speichern, setzt New SQL auf eine Verteilung der Daten auf Knoten.
Damit wird erreicht, dass alle Daten auf unterschiedliche Knoten gespeichert und damit getrennt werden. Wie die Knoten physisch angelegt sind bleibt dabei offen. Dies können unterschiedliche Festplatten in einem Server, verschiedene Server an verschiedenen Standpunkten usw. sein. Google bspw. hat seine Knoten über die ganze Welt verteilt.
Sharding und Replication/Replizieren
Hier kommen auch die Begriffe Sharding und Replication ins Spiel. Sharding beschreibt dabei die Verteilung auf verschiedene Knoten und Replication die Replizierung von Daten (Partitionen) auf verschiedenen Knoten. Der Vorteil dabei ist, dass billigste Hardware nebeneinander gestellt werden kann und die Daten darauf verteilt werden.
Layer 3: Data Persistenz
Die unterste Schicht Data Persistenz kümmert sich um das physische: wie werden die Daten abgelegt. Dabei spielt das DFS (Distributed File System) eine große Rolle, welches die Knotenorientierung auffängt.
GFS
Google hat bspw. in der eigenen NewSQL-Datenbank „Google BigTable“ das GFS (Google File System) implementiert. Dieses sagt dass jede Datei maximal 200 MB groß sein ,darf ansonsten wird sie mit „Snappy“ (ebenfalls eine Google Entwicklung, ähnlich wie 7zip) komprimiert.
Spaltenorientierung
Die Spaltenorientierung ist eine weitere gravierende Abweichung zur klassischen RDBMS. In NewSQL werden nun nicht mehr Zeilen betrachtet und gespeichert, sondern Spalten. Das ist nicht zuletzt dem Fakt geschuldet, dass die Abfrage von einzelnen Spalten 75 % der gesamten Abfragen ausmacht. Nur in 25 % der Fälle werden ganze Zeilen Abgefragt.
Ein weiterer Vorteil der Spaltenorientierung ist die, dass Indizes – die per se auf Spalten angewendet werden – geschlossen in einer Datei gespeichert werden können.


Neueste Kommentare